
SYNTHETIC ABSTRACTIONS
The following text and interview were written by Anika Meier.
PIONEERS is a new objkt gallery dedicated to showcasing paradigmatic artworks from key figures in the history of digital art, presented by our curators and guest curators specialized in the field of generative art, AI, and media art.
Tom White’s series Synthetic Abstractions (2018) is the first release as part of PIONEERS. In conversation with Anika Meier, Tom White talks about the collection and his history working with AI and generative code for the past 25 years.

Mustard Dream, 2018, Tom White.
Anika Meier: When did you first hear about AI, and what were your thoughts back then?
Tom White: I studied AI over 25 years ago, including taking courses at MIT, including those taught by Marvin Minsky, Rodney Brooks, and Deb Roy. It has always been clear that this field would have a huge impact on technology and society.
The definition of AI has changed in various ways over the years. For example, the AI that Harold Cohen or Karl Sims worked on in the ’90s is only similar to today's AI at a very high level—so much has changed between then and now.
I think the overall arc or backstory is relatable. I've always been equally interested in AI and programming, so it's hard for me to separate the two. There’s a philosophical aspect to it that fascinates me—how to deconstruct things we intuitively know how to do and then recreate them. That idea runs through both generative art and programming. But I was always more drawn to the advanced version of that process, which is AI.
When I was doing my early projects in the ’90s, the artist who spoke to me the most was Karl Sims. What stood out to me in his work was his use of artificial evolution. What his work shares with modern AI is that the results aren’t directly programmed or designed—they're grown, almost like biological entities.
It's as if you're cultivating a garden: you set the starting conditions and control the rain and sunlight, but what actually grows is somewhat beyond your control. That, I think, is the core philosophical difference between AI and traditional generative programming. The latter is more of a top-down decomposition, whereas AI often evolves from the bottom up. That approach has always intrigued me.
The techniques have evolved over the years, and it was about a decade ago—when deep learning started to truly show its potential—that I committed more deeply to using deep learning and computer vision in my artistic investigations.

ACG research group in 2000 with Tom White (front right) and John Maeda (front left) along with Golan Levin, Jared Shiffman, Casey Reas, Ben Fry, and other researchers. © John Maeda
AM: You worked closely with John Maeda at MIT, where Casey Reas and Ben Fry created Processing. Maeda said in an interview with the Guardian: "We seem to forget that innovation doesn't just come from equations or new kinds of chemicals; it comes from a human place. Innovation in the sciences is always linked in some way, either directly or indirectly, to a human experience. And human experiences happen through engaging with the arts—listening to music, say, or seeing a piece of art." What are your experiences of working at MIT? Do you share that perspective?
TW: The goal of the group was never to create these libraries; that output was merely a by-product of everyone working on their own projects and engaging with their own experiences. So, I do agree that the primary focus needs to be on expression, with technology playing a supporting role in telling the story.
AM: You not only have a background in creative coding, but you were also interested in generative art. How did you learn about the history of early computer art, and is that connected to your own journey of learning how to code?
TW: My own journey of learning how to code was not directly a result of early computer artists. However, as I became more proficient, I began to be more influenced by other computational artists and their techniques.
How my background prepared me to explore GANs really goes all the way back to the late ’90s, when I was working at MIT. At the time, there weren’t any creative coding tools—there was no GitHub, no real infrastructure for sharing code or collaborating in the way we do now. You had to be a bit weird and adventurous just to get anything done.
What happened was that a group of like-minded people at the Media Lab—myself, Casey Reas, Golan Levin, and Ben Fry—started doing our own experiments. But we also decided to share code and ideas. We were building the foundational blocks for the kinds of creative, interactive experiences we wanted to make. That shared code eventually evolved into what we now know as Processing and OpenFrameworks. Those toolkits grew out of the trailblazing work we were doing at the code level.
That might seem like a roundabout way of explaining it, but I think that mindset—an open, exploratory approach to tools and technology—is what prepared me to embrace AI, especially when GANs emerged.
In many ways, GANs were intimidating. The technology felt unapproachable at first, but it was also incredibly exciting. I think part of what’s shaped my path over the years is a love for building my own software tools to explore ideas. Whether that means creating drawing tools to express myself graphically, or diving into GANs and building systems around them, that spirit of tool-making and experimentation has always been central to my practice.
AM: Who are some of the pioneers that have influenced you as an artist, and why?
TW: My primary influences early in my career were:
Myron Kruger: I worked closely with Myron as an intern and was influenced by his approach to computational art and his exploration of interaction as a medium in its own right.
Karl Sims: His early AI artwork in the 1990s was inspirational, and many of my initial projects were based on his ideas about generative programming.
Harold Cohen: One of the earliest AI artists and generative programmers, his work and writings were foundational in forging a path for artists combining visual arts and artificial intelligence.
One influence that I like to talk about, which is more traditional, is Stuart Davis.
Stuart Davis was a painter in the 1920s. When he was in school, one interesting experiment he did was to take a common set of items—an egg beater, an electric fan, and a rubber glove—and nail them to his work table in his studio. He forced himself to draw these things day after day for a year. What he was doing was trying to strip down his perception and force himself to see these objects in new ways.
He went on to become a successful artist and played a key role in influencing the early pop art movement, even before the 1950s. What he did there is something I see as a common approach among artists: they’re trying to see the world in a new way or push themselves into a different mode of perception so they can share that with others.
I draw inspiration from Stuart Davis's approach, except that, instead of meditating on an object or forcing myself to stare at something for a year, I use computational tools to assist me. For example, I can ask, "Here’s a vision system—how does it see the world?" Or, "If I take something apart and rebuild it using AI, how does it change?"
I think Stuart Davis’s Eggbeater Series is an important influence on my work, especially in terms of how I approach inspiration. Just like Davis looked for new ways to see, artists often seek unique perspectives by looking outside their usual frame of reference—whether by researching a different culture or exploring new ideas. In my case, I look at that same process, but through the lens of the machine.
AM: How has your background in creative coding influenced you since you started working with GANs?
TW: It was the experience of learning to adapt early technologies for creative purposes that best prepared me for working with GANs. I do think there's a craft to coding, and I'm proud of that craft. But that said, I don't think it should be a gateway or barrier—because my interest has always been in what's going on inside these machines and what these machines can teach us about ourselves.
I don't think a lot of the tools that can draw images for you or write code for you will actually answer those kinds of questions. They can help you form an answer, but they won't provide the answer themselves. So, I don't see these tools automating my work away. They might make parts of it easier, and I generally welcome that.
It's something I also bring into my teaching. I teach at a design school, and I focus on the philosophy of how to use these tools—even for students who have no background in coding or programming. A lot of them come in a little suspicious, but I think that's okay. I think it's good. It's part of being literate today.
It would be like teaching a photography class and only covering film without mentioning digital photography. That wouldn’t make sense anymore. In the same way, understanding how programming works—and now how AI works—is useful for everyone.
AM: How do you explain what you did back then to people who don’t have a deep understanding of machine learning?
TW: When I began exploring the creative applications of deep learning research ten years ago, there was very little support for code or model sharing. I was working with models such as Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs) as new computational approaches to generating imagery. These systems offered a new set of primitives—very different from the "DrawLine"-style commands found in traditional creative coding platforms.
AM: Why did you decide to train your own model, and what were you interested in exploring back then?
TW: I have occasionally trained my own models on custom data, but my primary interest lies in large-scale pre-trained models. Specifically, I’m fascinated by the knowledge embedded within these systems and the unique ways they interpret and understand the world.
AM: What were some of the challenges you encountered along the way?
TW: The main challenge is that the field of AI is constantly evolving and accelerating. Techniques that are considered breakthroughs one year can become routine the next. I’ve had to continually adapt my practice to keep up with the latest trends and capabilities in the field.
AM: What are your criteria for good AI art?
TW: My preference is for art that reflects the true nature of the artificial intelligence processes being used and that also illuminates the culture and capabilities of these thinking machines.
AM: When we hear discussions about art created with AI, they’re often focused on the technology. What is your point of view on the conversation 'No tech demos, please!'?
TW: It’s a tricky question because errors can be made on both sides. While art should not merely serve as a technology demo, it’s equally common for AI art to be presented without a solid grounding in contemporary machine learning. It’s important to balance creative expression with a genuine desire to allow the AI to express itself as part of the process.
A lot of this has happened before with photography, and I think that's a great analogy that others have used. In the past, to have your portrait made, you had to sit for someone who would paint it. Then, photography came along, and it was mechanical—you could capture an image with the push of a button. But that doesn’t mean everyone is a great photographer. There are still skills involved. Suddenly, the image itself was somewhat devalued because everyone had access to it.
But I think another, deeper answer to what you're asking is that I actually welcome it. There are a million different reasons to make art and appreciate art, but sometimes it's useful to think of it all on a spectrum of content and form. What these tools are doing is making the form accessible to everyone. Now, everyone can create visually literate works, but they’re not yet offering much assistance on the content side. And that’s the side I’ve always been interested in.
I’ve never been interested in algorithmic works solely for their surface appeal. What interests me is whether these computer vision systems work the same way we do when we look at something. Are they seeing the same thing? How can I communicate these ideas visually?
This background story is important. Anything that makes it easier for me to tell that story, I welcome. However, I think if you're an artist who’s only focused on a weird visual technique or doing something purely based on form, you might be in more trouble. Those are the things that AI can automate more easily.
AM: Your series Synthetic Abstractions is about— in short— abstract pornography and the difference between what humans see and what machines see. Why did you create this series?
TW: In contemporary AI discussions, there is significant debate and research on how to ensure that AI is "aligned" with human values. This work began before the research gained widespread attention but shares many of its foundational ideas. I am fascinated by how humans and machines perceive objects—sometimes in similar ways and sometimes in very different ones.
The Synthetic Abstractions series was about embracing this difference and creating examples of extreme "misalignment," where innocuous abstract art is perceived as harmful or threatening by common computer vision systems, such as Google SafeSearch.

AM: Speaking about Synthetic Abstractions, it's interesting because some platforms, like Object, automatically block content if they detect pornographic material. Sometimes, I find myself wondering, "Why was this blocked? I don't even know." And that's essentially what your project is about, right? You've flipped the process around.
TW: That's right. I was working on a series before Synthetic Abstractions called Perception Engines. These were common everyday objects like a cello and an electric fan. I could show those, but they weren’t as surprising to people. I thought they were interesting because they represented primitive, abstract ways in which computers were recognizing objects.
Then, I created Synthetic Abstractions, where I applied the same concept but focused on pornography filters. Specifically, I used filters that worked well with SafeSearch. Even now, I’m still surprised by the results. For example, if you search for "Tom White synthetic abstractions" on Google Image Search, it will blur out many of the images. The reason it blurs them is because when the system sees one of these images—like Mustard Dream or any of the other pieces—it triggers Google SafeSearch. This is fascinating to me because it’s been about seven or eight years since I first worked on this, and you'd expect the vision systems or the quirks I was exploiting to have been fixed by now. But no, there’s something deep within these systems that still triggers these algorithms, and I find that amazing.

I don't fully understand why this happens, but I’ve found ways to shape the artwork so that it reliably triggers these filters. It was designed to do that intentionally. However, when people ask me whether the images depict a woman or a man, or whether there’s nudity, I don’t know. When I show them to platforms like Amazon, they often classify the images, stating things like "nudity present." Sometimes, the system even gives me a hint of what it thinks it sees, but in general, I don’t know what it is that specifically triggers the filter.
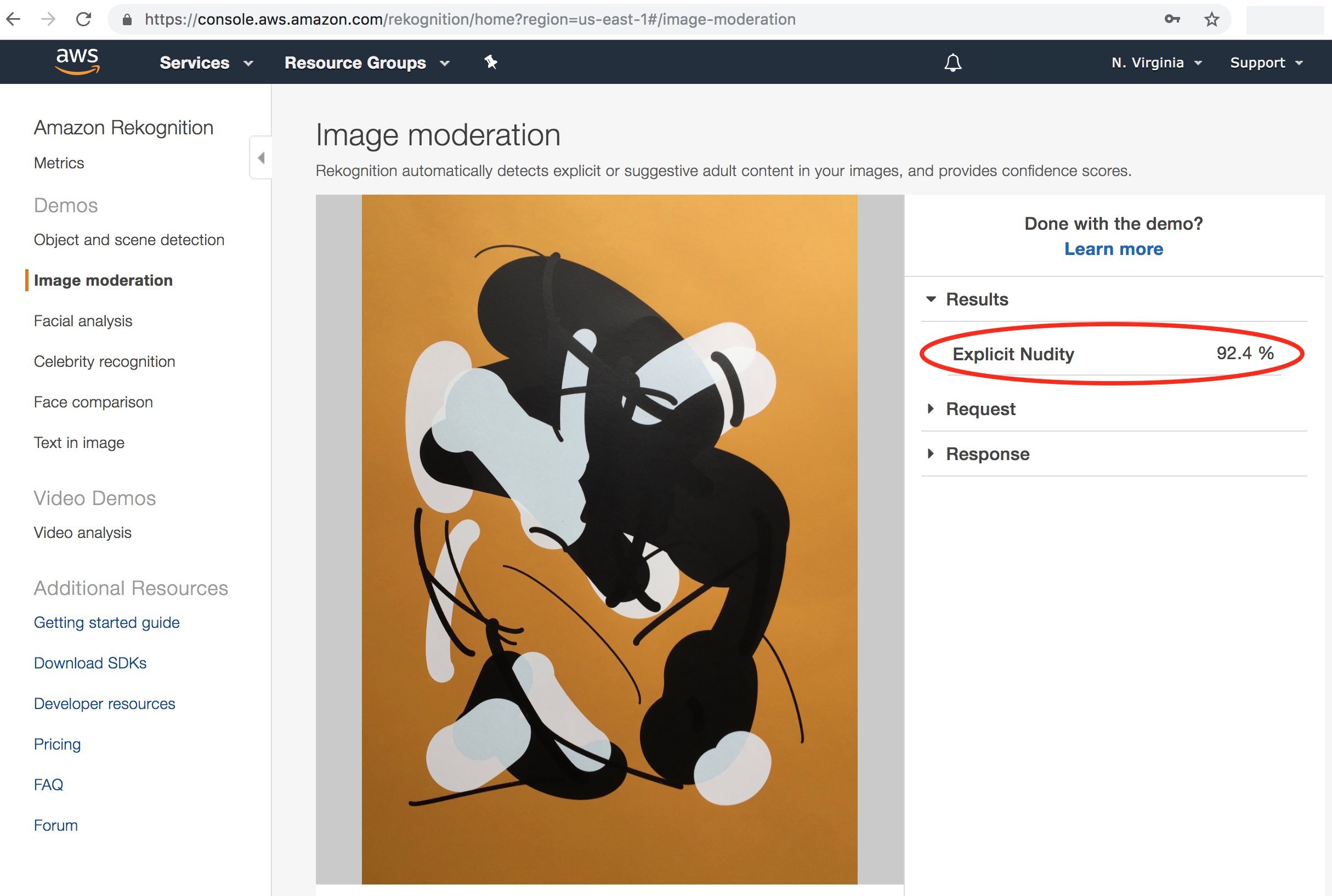
It still works on Google SafeSearch, though I don’t know how many times they’ve updated their algorithms in the last five or ten years. Maybe they have newer algorithms mixed with older ones or something like that. But I do know that if you do a web search—I'll send you a link after the call—you can search for something like Synthetic Abstractions or Mustard Dream. If you do a Google Image search, you'll see three or four responses, and two or three of them will be blurred out because the system will flag them with a message like, "This looks like something I shouldn't show you," which was, of course, the point.
At the time, I had a lot of things like this happen. I tried posting these images to a blogging platform— I think it was Tumblr, but I'll double-check. I have a screenshot from when I tried to post them, and the platform would block the post because it often flagged the images as "not community-friendly" or something similar. It's funny, because all the filters use different wording for the same thing.



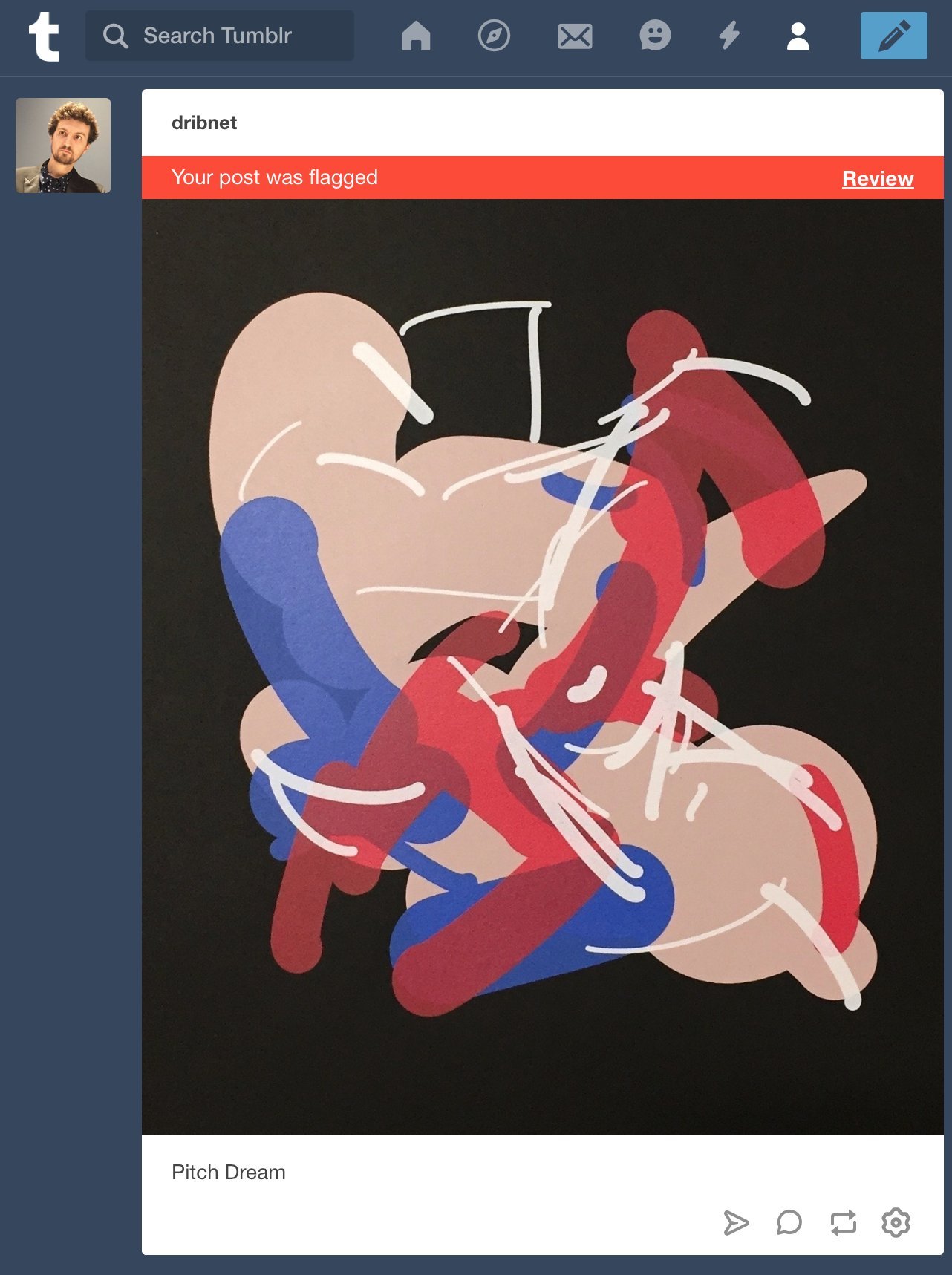
It was really a moment of its time. When I first made these works, it was quite effective. It’s less effective now, though, because the algorithms have improved. But it's not completely gone— even Google SafeSearch will still show it if you look closely.
I know how to target the filter, but I don’t know exactly what in the training set is causing the trigger. At the time, I was also getting into screen printing, and I’m really proud of the results.
The artwork is designed as layered screen prints, so what we're selling on Objkt are the digital masters. These can look a bit different because once I get into the studio, I start mixing ink, and the prints turn out a little differently. But those digital masters are what I use to create the screen prints, and they are planned with three or four layers of ink.
AM: That's great! Also, the fact that you call them digital masters sounds like you're selling the master tapes of, I don't know, Stairway to Heaven by Led Zeppelin.
TW: It kind of is the case, because these are the images that initially triggered the algorithm. Now, I test the prints to make sure they still trigger the filters, but often the prints don't elicit as strong a response as the digital version. So, I design them on the computer, ensuring that the image works under different lighting conditions and angles. Then, when I actually print it, I keep my fingers crossed that it works. Fortunately, all the prints I’ve done have worked.
These are the digital masters, though. The work was originally designed with optimization to trigger the filters. It was created first as a digital image and then converted into ink layers.

AM: Did you consider yourself an artist when you created Synthetic Abstraction?
TW: I definitely considered myself an artist foremost when I created Synthetic Abstraction. I had already had an exhibition the year before in New Delhi, called Gradient Descent, and I had been in other art shows. As a bit of background, when I graduated from MIT, much of the artwork I created was interactive and multimedia. These were media installations, often involving projectors, dark rooms, computers, and other elements. I created a lot of these installations, and some of them were quite successful. They even toured with Ars Electronica and similar exhibitions.
However, when I started exploring AI art about ten years ago, I became fascinated with print work. The AI had become sophisticated enough to interpret print work and form its own opinions about it. The boundary between the digital and physical worlds was also becoming increasingly blurred. What I mean by that is, if I visit a gallery and see something hanging on the wall, I might take a picture of it with my phone and post it on Instagram. Right away, that image enters the digital realm. The lines between the two worlds were becoming thinner and thinner. This is when I began to experiment with print work for the first time, using computational tools.
To answer your question directly, when I worked on Synthetic Abstractions in 2017, I was comfortable calling myself an artist, and what I was doing was very much in the context of art creation.
In 2016, I had already transitioned into education. I was teaching at an art and design school, working with undergraduate designers, while also maintaining my own art practice in the studio. By then, I think I was fully committed to the role, and any reservations I had about not calling myself an artist had faded away.
AM: You coined the term Algorithmic Gaze. How has the Algorithmic Gaze evolved since you started working with it?
TW: There have been three main waves in computer vision since I began this work. In Synthetic Abstractions, all computer vision systems were trained on supervised datasets, meaning their ontology was fixed and rigid. This meant that the Algorithmic Gaze was only initially prepared to recognize objects it had been explicitly trained on. Later, with the emergence of large language models, computer vision systems were trained on internet corpora of images and captions. These systems could leverage the full power of language to constrain their operations, no longer being limited to specific training classifications. In the latest AI wave, the Algorithmic Gaze can be decomposed into atomic units using mechanistic interpretability techniques and can also use inference-time computation to extend its thinking and reason logically about scenes. Each of these developments has expanded the Algorithmic Gaze with new capabilities relative to earlier systems, but at each stage, these systems remain non-human and have their own unique way of parsing the world.